Tabla de contenidos
En este mundo interconectado, cada acción que realizamos se convierte en un dato. Desde la búsqueda de información en internet hasta la interacción en redes sociales, pasando por las compras online y el visionado de series en plataformas de «streaming». Todos estos datos necesitan ser almacenados, gestionados y procesados de manera eficiente para que la información esté disponible al instante. Aquí es donde entra en juego el mundo de las bases de datos.

Las bases de datos no son solo el corazón de casi todas las aplicaciones web y servicios que usamos a diario, sino que también son imprescindibles en ámbitos tan variados como la medicina, para el seguimiento de historiales clínicos; la meteorología, en la predicción del tiempo; o incluso en el deporte, para analizar el rendimiento de los atletas.
Por ejemplo, cada vez que usamos una aplicación para monitorizar nuestras rutas de «running», estamos viendo nuestro progreso al mismo tiempo que estamos interactuando con bases de datos que almacenan y procesan nuestras distancias, rutas, tiempos y comparativas.
Las bases de datos se han vuelto imprescindibles en la era de la «big data», donde la capacidad de procesar rápido enormes cantidades de información puede ser la diferencia entre tomar una decisión acertada o quedarse atrás.
Por ejemplo, las recomendaciones personalizadas que nos hacen las plataformas de comercio electrónico se basan en complejos análisis de datos almacenados sobre nuestros hábitos de compra y preferencias.
Adentrarnos en el estudio de las bases de datos nos permitirá comprender cómo se estructuran los datos en tablas, registros y campos, cómo se definen y manipulan mediante lenguajes específicos como SQL, y cómo se pueden extraer informaciones valiosas a través de vistas, informes y formularios. Además, exploraremos las diferencias entre los sistemas gestores de bases de datos relacionales, fundamentales para entender la lógica detrás del almacenamiento de datos interrelacionados, y las bases de datos NoSQL, fundamentales para manejar volúmenes de datos masivos que no se ajustan bien a esquemas predefinidos.
La habilidad para gestionar y analizar datos se ha convertido en una competencia clave en el mercado laboral actual. En este sentido, conocer el funcionamiento y la aplicación de las bases de datos nos abre las puertas a una amplia gama de oportunidades profesionales.
8.1. Sistemas gestores de bases de datos relacionales.
Es fundamental comprender que estamos hablando de una herramienta clave en el mundo de la informática y la gestión de la información.
Pero antes de conocer qué es un Sistema Gestor de Bases de Datos -SGBD-, necesitamos saber qué es una base de datos.
Una base de datos es un conjunto de información estructurada relativa a un tema determinado. Este tema puede englobar un gran número de contextos de los que nos interesa mantenernos al tanto y que queremos tener frecuentemente actualizados.
Prácticamente cualquier sistema de información o conocimiento puede estructurarse y clasificarse en una base de datos.
Hasta hace relativamente pocos años, las bases de datos eran analógicas, es decir, contenían información en papel o textos impresos. Sin embargo, con la llegada de la era digital y el Big Data se ha hecho imprescindible el uso de bases de datos informatizadas.
Gracias a las bases de datos en formato digital se han podido solucionar muchos de los problemas que surgían a raíz de la ingente cantidad de información que se maneja en la actualidad.
Por ejemplo, permiten ahorrar espacio, agilizar las consultas y se puede almacenar mucha más información. ¿Te imaginas lo engorroso que sería obtener el listado de publicaciones de un usuario de una red social si todo estuviera almacenado en papel?
Los programas que han hecho esto posible se denominan Sistemas Gestores de Bases de Datos (SGBD) o, en inglés, Database Management System (DBMS). Este tipo de programas facilitan enormemente el almacenamiento de datos y la posterior consulta de los mismos. En un principio eran usados sobre todo por grandes empresas o administraciones públicas, pero en la actualidad también los emplean todo tipo de usuarios o empresas (por ejemplo, para crear el registro de usuarios de una web).
Los SGBD no solo almacenan datos de manera eficiente, sino que también permiten su recuperación, actualización y gestión a través de relaciones lógicas entre ellos.
Estos sistemas se basan en el modelo relacional de datos, un enfoque que organiza la información en tablas compuestas por filas y columnas.
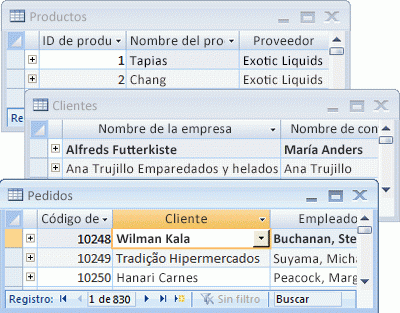
Los SGBD funcionan bajo el principio de que cada dato está relacionado de alguna manera con otro, permitiendo así consultas complejas y el mantenimiento de las relaciones entre los datos a través de reglas definidas.
Esta capacidad para establecer relaciones complejas entre diferentes tablas es lo que los hace tan potentes para el manejo de grandes volúmenes de información estructurada.
Pero, esa es solo la punta del iceberg, ya que un SGBD nos ofrece toda esta funcionalidad:
- Definición de datos: permiten la creación y modificación de la estructura de las bases de datos a través de un Lenguaje de Definición de Datos (DDL). Esto incluye la creación de tablas, definición de campos, y establecimiento de restricciones y relaciones entre tablas.
- Manipulación de datos: ofrecen herramientas para insertar, actualizar, borrar y consultar datos almacenados, utilizando un Lenguaje de Manipulación de Datos (DML). Estas operaciones son fundamentales para el manejo diario de los datos dentro de la base de datos.
- Control de transacciones: gestionan transacciones, que son secuencias de operaciones de manipulación de datos tratadas como una sola unidad. Esto asegura la integridad de los datos a través de propiedades como la atomicidad, consistencia, aislamiento y durabilidad (ACID).
- Seguridad: proveen mecanismos para controlar el acceso a los datos, asegurando que solo usuarios autorizados puedan realizar operaciones específicas. Esto incluye la gestión de permisos y roles, así como la implementación de políticas de seguridad para proteger los datos.
- Integridad de datos: mantienen la precisión y consistencia de los datos a través de restricciones de integridad, unicidad y de chequeo, que aseguran que los datos almacenados cumplan con reglas específicas.
- Consultas avanzadas: permiten la realización de consultas complejas utilizando el Lenguaje de Consulta Estructurada (SQL), incluyendo operaciones como «join», subconsultas, funciones agregadas y vistas, para extraer información significativa de los datos almacenados.
- Optimización de consultas: incluyen optimizadores de consultas que analizan y determinan la manera más eficiente de ejecutar una consulta, mejorando el rendimiento de la base de datos.
- Soporte para procedimientos almacenados: permiten definir procedimientos en la propia base de datos, que se ejecutan automáticamente en respuesta a eventos específicos, mejorando la eficiencia y centralizando la lógica de negocio.
- Gestión de la concurrencia: gestionan el acceso concurrente a los datos para asegurar que múltiples usuarios puedan trabajar con la base de datos simultáneamente sin interferir entre sí, mediante el control de bloqueos y versiones de datos.
- Copia de seguridad: ofrecen herramientas para crear copias de seguridad de los datos y recuperar la base de datos en caso de fallos o pérdida de datos, asegurando su disponibilidad.
- Soporte para datos masivos: algunos SGBD están diseñados para manejar grandes volúmenes de datos por lo que ofrecen funcionalidades muy demandadas en este tipo de tareas.
Un ejemplo práctico de la aplicación de los SGBD lo encontramos en el sector bancario, donde es vital gestionar enormes cantidades de datos relacionados con clientes, cuentas, transacciones y préstamos. Un SGBD permite a los bancos almacenar estos datos de forma segura, realizar operaciones como actualizar saldos de cuentas, procesar pagos y generar informes financieros de manera eficiente.
Entre los SGBD más destacados hoy en día se encuentran MySQL, Oracle Database, Microsoft SQL Server y PostgreSQL. Cada uno de estos sistemas tiene sus propias características, ventajas y desventajas, pero todos comparten la capacidad de trabajar con datos relacionales de manera eficiente.

MySQL: ampliamente utilizado en aplicaciones web, es conocido por su simplicidad y eficacia en el manejo de sitios web dinámicos.

Oracle Database: ofrece una solución robusta para grandes empresas, destacando por su escalabilidad, seguridad y conjunto de características para el procesamiento de transacciones complejas.

Microsoft SQL Server: integrado estrechamente con productos Microsoft, es ideal para entornos que ya dependen de la infraestructura de Microsoft.

PostgreSQL: un sistema de código abierto, resalta por su conformidad con los estándares SQL y su capacidad para manejar una amplia gama de cargas de trabajo, desde simples consultas hasta análisis de datos complejos.
8.2. Tablas, registros y campos. Tipos de datos.
En el núcleo de los sistemas gestores de bases de datos relacionales se encuentran las tablas, registros, y campos, conceptos fundamentales que estructuran la manera en que se almacena y organiza la información.
Este esquema facilita almacenamiento de datos de manera sistemática y eficiente, su recuperación, actualización y gestión.
Vamos a desglosar cada uno de estos elementos y cómo interactúan entre sí para formar la base de cualquier base de datos relacional.
8.2.1. Tablas
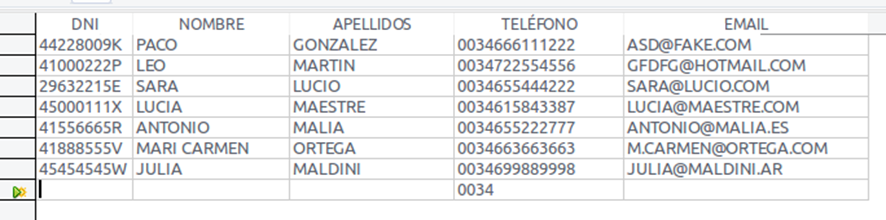
Una tabla es una estructura que organiza datos en filas y columnas, de manera similar a como se visualiza una hoja de cálculo.
Cada tabla almacena datos sobre un tipo específico de entidad, por ejemplo, clientes, productos, o pedidos.
Este es el aspecto de una tabla que almacena datos personales:
8.2.2. Registros
Un registro (también llamado fila o tupla) en una tabla representa un único elemento o instancia de la entidad que describe la tabla.
Por ejemplo, en una tabla de clientes, un registro sería un cliente específico con todos los campos.
Siguiendo con el ejemplo anterior, cada fila sería un registro, en la siguiente tabla hay 7 registros:
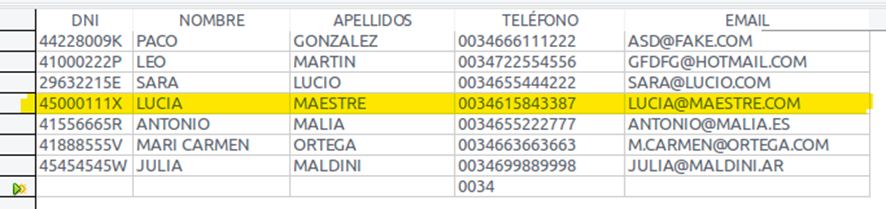
8.2.3. Campos
Los campos (también llamados columnas o atributos) son los componentes individuales de información en un registro.
Cada campo tiene un tipo de dato específico que define la naturaleza de los datos que puede contener, como texto, números, fechas, etc.
Por ejemplo, un campo «Nombre de Cliente» puede ser de tipo texto, mientras que un campo «Fecha de Nacimiento» sería de tipo fecha.
Los SGBD soportan diversos tipos de datos para adaptarse a las necesidades específicas de almacenamiento de información.
El tipo de dato se define sobre cada campo -columna-, cuando estamos creando la tabla.
Modificar el tipo de dato de un campo una vez que la tabla está cargada de registros, es mala idea, ya que podrían producirse inconsistencias.
Estos tipos de datos incluyen:
- Texto: para almacenar cadenas de caracteres, como nombres, direcciones o descripciones.
- Números: existen varios tipos numéricos, incluidos enteros y decimales, para almacenar números con o sin decimales.
- Fecha y hora: para almacenar fechas, horas o ambas, permitiendo realizar operaciones como cálculos de intervalos o comparaciones de fechas.
- Booleano: para almacenar valores verdadero o falso, útil para definir campos con solo dos posibles valores, estados o condiciones.
- Blob (Binary Large Object): para almacenar datos binarios, como imágenes, archivos de audio o cualquier otro tipo de archivo multimedia.
8.3. Claves y relaciones
En el universo de las bases de datos relacionales, las claves y relaciones nos permiten establecer conexiones lógicas entre los distintos datos almacenados. Estos conceptos son fundamentales para asegurar la integridad de los datos, evitar duplicidades innecesarias y facilitar la recuperación eficiente de la información.
8.3.1. Claves
Una clave es un atributo o conjunto de atributos que sirve para identificar de manera única cada registro dentro de una tabla.
Las claves juegan un papel vital en el mantenimiento de la integridad de los datos y en la definición de las relaciones entre tablas.
Existen varios tipos de claves, pero las dos más importantes son estas:
- Clave primaria (primary key): un atributo o conjunto de atributos que identifica de manera única cada registro en una tabla. No puede haber dos registros en una tabla con la misma clave primaria, y no puede ser nula.
- Clave foránea (foreign key): un atributo en una tabla que es la clave primaria en otra tabla. Las claves foráneas se utilizan para establecer y hacer cumplir una relación entre dos tablas.
Es obligatorio definir una clave primaria para cada tabla de una base de datos.
Por ejemplo, si tenemos una tabla -como la que hemos visto más arriba- de alumnos, ¿qué atributo sería clave primaria?
Para responder a esta pregunta debemos preguntarnos: ¿qué atributo hace que cada alumno sea distintos de todos los demás? Si lo piensas por un momento, llegarás a la conclusión que el DNI es el dato que identifica unívocamente a cada alumno, y en general, a cada persona. Por tanto, el campo DNI sería la clave primaria de la tabla ALUMNOS.
Consideremos ahora estas dos tablas, que formarían parte de una hipotética base de datos llamada TALLER. En nuestra aplicación para gestionar un taller de coches, habrá varias tablas, pero dos de ellas serán: PROPIETARIO y VEHÍCULO:
PROPIETARIO
| DNI | Nombre | Apellidos | Teléfono |
| 45112558B | Juan | Méndez Álvarez | 665000111 |
| 27000112Z | Erik | García Castaño | 778552121 |
| 41445698K | Sergio | López Toledo | 615804142 |
VEHÍCULO
| Matrícula | Marca | Modelo | Cilindrada |
| 3399GHF | Toyota | Corolla | 1.9 |
| 5641BCD | Mercedes | CLA | 1.6 |
| 9099KDF | Nissan | Primera | 2.5 |
Como puedes ver, la tabla PROPIETARIO tiene una clave primaria -el DNI– que identifica de forma única a cada propietario. De la misma manera, la tabla VEHÍCULO tiene una clave primaria -la Matrícula– que identifica de manera única a cada vehículo.
Pero las tablas no están relacionadas, es decir, no sabemos quién es el propietario de cada vehículo, lo cual hace imposible gestionar los pagos de las reparaciones que se le hagan a ese vehículo.
Es necesario, añadir algún campo a la tabla VEHÍCULO que nos permita relacionar cada vehículo con su propietario.
VEHÍCULO
| Matrícula | Marca | Modelo | Cilindrada | Propietario |
| 3399GHF | Toyota | Corolla | 1.9 | 27000112Z |
| 5641BCD | Mercedes | CLA | 1.6 | 27000112Z |
| 9099KDF | Nissan | Primera | 2.5 | 45112558B |
Ahora, sí que sabemos que el Toyota y el Mercedes son de Alberto, y el Nissan es de Juan. A este campo que hemos añadido en la tabla VEHÍCULO -Propietario- es al que llamamos clave foránea, porque nos permite relacionar cada fila de la tabla VEHÍCULO con una fila de la tabla PROPIETARIO.
Esta relación debemos dejarla establecida diseñando un diagrama relacional de la base de datos. En el ejemplo anterior, sería:
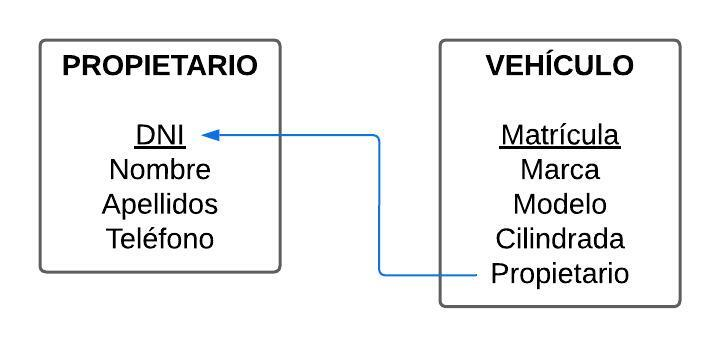
Cuando diseñamos una base de datos es completamente imprescindible definir tanto las claves primarias de todas las tablas, como las claves foráneas que nos permitan relacionar unas tablas con otras.
Ejercicio resuelto – YouTube DB
Todos sabemos cómo funciona YouTube, pero es un gigante que almacena montones de datos de todo lo que ocurre, y no todos esos datos son evidentes. Centrémonos en los más visibles: tenemos unos usuarios que suben vídeos, comentan y se suscriben. Además queremos llevar la cuenta de las visualizaciones por país, para ver las tendencias de cada zona geográfica.
Así, a primera vista tendríamos estas 5 tablas: USUARIOS, VÍDEOS, COMENTARIOS, SUSCRIPCIONES, VISUALIZACIONES_PAÍS.
Si reflexionamos un poco, no será complicado extraer los campos que tendría cada tabla:
- USUARIOS:
- UsuarioID
- Nombre
- FechaRegistro
- País
- VÍDEOS:
- VideoID
- Título
- UsuarioID
- FechaSubida
- Visualizaciones
- Likes
- COMENTARIOS:
- ComentarioID
- VideoID
- UsuarioID
- Fecha
- Contenido
- SUSCRIPCIONES:
- UsuarioID_Suscriptor
- UsuarioID_Suscrito
- FechaSuscripción
- VISUALIZACIONES_PAÍS:
- VideoID
- País
- Fecha
- Visualizaciones
¿Qué campos son las claves primarias de cada tabla?
USUARIO (UsuarioID)
VÍDEOS (VideoID)
COMENTARIOS (ComentarioID)
SUSCRIPCIONES (UsuarioID_Suscriptor, UsuarioID_Suscrito)
VISUALIZACIONES_PAIS (VideoID, País, Fecha)
Además, observando la definición de los campos que hemos hecho, parece evidente qué campos estarían funcionando como claves foráneas. Para ver esto con más claridad, podemos construir su diagrama relacional:
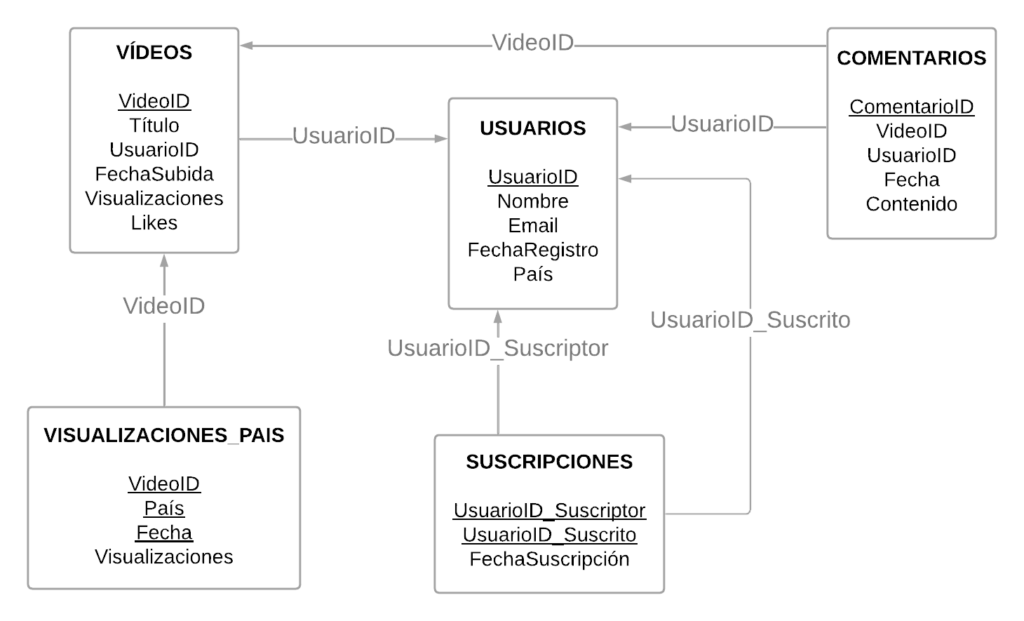
Finalmente, podemos escribir el contenido de ejemplo de esas 5 tablas con algunos registros, para terminar de redondear la comprensión de esta base de datos:
USUARIOS
| UsuarioID | Nombre | FechaRegistro | País | |
| User001 | JuanVlogs | juanvlogs@email.com | 2022-01-15 | España |
| User002 | MartaGamer | martagamer@email.com | 2022-02-20 | España |
| User003 | CarlosTech | carlostech@email.com | 2022-03-25 | España |
| User004 | AnaCooks | anacooks@email.com | 2022-04-30 | España |
| User005 | PedroMusic | pedromusic@email.com | 2022-05-05 | España |
VIDEOS
| VideoID | Título | UsuarioID | FechaSubida | Visualizaciones | Likes |
| Vid001 | “Viaje a Sevilla” | User001 | 2022-06-10 | 15000 | 3000 |
| Vid002 | “Partida épica de Fortnite” | User002 | 2022-07-15 | 25000 | 5000 |
| Vid003 | “Novedades en tecnología móvil” | User003 | 2022-08-20 | 20000 | 4000 |
| Vid004 | “Receta de paella” | User004 | 2022-09-25 | 10000 | 2000 |
| Vid005 | “Concierto acústico en casa” | User005 | 2022-10-30 | 5000 | 1000 |
COMENTARIOS
| ComentarioID | VideoID | UsuarioID | Fecha | Contenido |
| Com001 | Vid001 | User002 | 2022-06-11 | “¡Fantástico viaje!” |
| Com002 | Vid002 | User003 | 2022-07-16 | “Increíble partida, ¡bien jugado!” |
| Com003 | Vid003 | User004 | 2022-08-21 | “Muy interesante, gracias por la info” |
| Com004 | Vid004 | User005 | 2022-09-26 | “Tengo que probar esa receta” |
| Com005 | Vid005 | User001 | 2022-10-31 | “Gran concierto, ¡me encanta!” |
SUSCRIPCIONES
| UsuarioID_Suscriptor | UsuarioID_Suscrito | FechaSuscripción |
| User001 | User002 | 2022-02-01 |
| User002 | User003 | 2022-03-02 |
| User003 | User004 | 2022-04-03 |
| User004 | User005 | 2022-05-04 |
| User005 | User001 | 2022-06-05 |
VISUALIZACIONES_PAÍS
| VideoID | País | Fecha | Visualizaciones |
| Vid001 | España | 2022-06-10 | 14000 |
| Vid002 | España | 2022-07-15 | 24000 |
| Vid003 | España | 2022-08-20 | 19000 |
| Vid004 | España | 2022-09-25 | 9000 |
| Vid005 | España | 2022-10-30 | 4000 |
8.3.2. Relaciones
Las relaciones definen cómo las tablas se conectan entre sí en una base de datos relacional. Estas conexiones son muy importantes para organizar los datos de manera lógica y para facilitar la recuperación de información compleja a través de consultas.
Existen tres tipos principales de relaciones:
- Relación uno a uno (1:1): cada registro en la primera tabla se relaciona con un máximo de un registro en la segunda tabla, y viceversa. Este tipo de relación es menos común pero se utiliza para dividir una tabla por razones de seguridad o para mejorar el rendimiento. Por ejemplo, si tuviéramos una tabla con los datos personales de una persona y otra tabla con los datos de acceso a una web -usuario y contraseña- esta sería una relación 1 a 1, porque las credenciales de accesos son exclusivas de una persona, y una persona no puede tener varias credenciales de acceso.
- Relación uno a muchos (1:N): un registro en la primera tabla puede estar relacionado con uno o varios registros en la segunda tabla, pero un registro en la segunda tabla solo puede estar relacionado con un registro en la primera tabla. Este es el tipo de relación más común en las bases de datos relacionales.
- Relación muchos a muchos (N:M): registros en la primera tabla pueden estar relacionados con múltiples registros en la segunda tabla, y viceversa. Este tipo de relación generalmente requiere una tabla intermedia o de unión para gestionar las relaciones entre las tablas. Por ejemplo, si tenemos una tabla ESTUDIANTES y una tabla ASIGNATURAS, estaríamos en una relación N a M, puesto que un estudiante puede tener varias asignaturas, y una asignatura puede ser escogida por varios estudiantes. Para discriminar qué estudiante cursa cada asignatura, crearíamos una tabla llamada MATRICULA. De esta manera, en la tabla ESTUDIANTES sólo habría datos personales, en la tabla ASIGNATURA sólo datos propios de cada asignatura y con la tabla MATRÍCULA controlaríamos quién asiste a qué asignaturas.
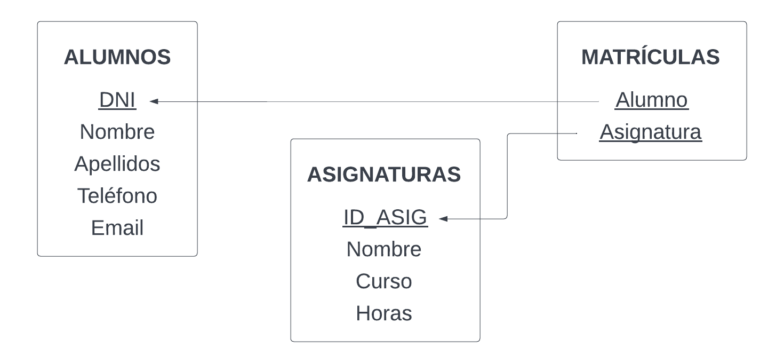
Cuando diseñamos bases de datos siempre es un ejercicio recomendable reflexionar sobre el tipo de relación que involucra a las tablas.
8.4. Lenguajes de definición y manipulación de datos. Comandos básicos en SQL.
El estudio de las bases de datos relacionales nos lleva inevitablemente a SQL –Structured Query Language–, el lenguaje estándar utilizado para interactuar con sistemas gestores de bases de datos relacionales.
SQL se divide en varios componentes, entre los que destacan el Lenguaje de Definición de Datos -DDL-, por sus siglas en inglés- y el Lenguaje de Manipulación de Datos -DML-.
Cada uno de estos componentes cumple funciones específicas que permiten a los usuarios definir la estructura de la base de datos, insertar, consultar, actualizar y borrar datos. Vamos a explorar los comandos básicos de SQL dentro de estas categorías.
8.4.1. Lenguaje de definición de datos
El DDL permite a los usuarios definir y modificar la estructura de la base de datos. Los comandos básicos incluyen:
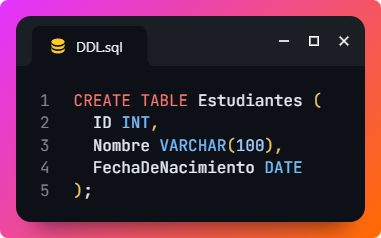
- CREATE: utilizado para crear nuevas tablas, bases de datos, índices, etc. Por ejemplo, este comando crea una nueva tabla llamada Estudiantes:
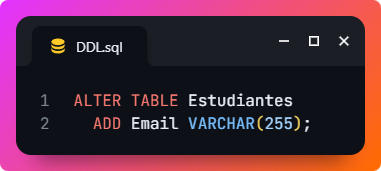
- ALTER: permite modificar la estructura de una tabla existente, como agregar o eliminar columnas. Por ejemplo, este comando añade una columna de correo electrónico a la tabla Estudiantes:
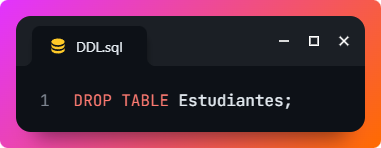
- DROP: se utiliza para eliminar tablas, bases de datos, índices, etc. Por ejemplo, este comando eliminaría la tabla Estudiantes:
- TRUNCATE: borra todos los registros de una tabla sin eliminar la tabla en sí. Esto es útil para reiniciar rápidamente los datos de una tabla.

En las prácticas asociadas a este apartado, que aparecen a continuación, veremos todas las posibilidades que tenemos cuando trabajamos con estos y otros comandos de SQL para la definición de datos:
8.4.2. Lenguaje de manipulación de datos
El DML permite a los usuarios realizar operaciones sobre los datos almacenados en la base de datos. Los comandos básicos incluyen:
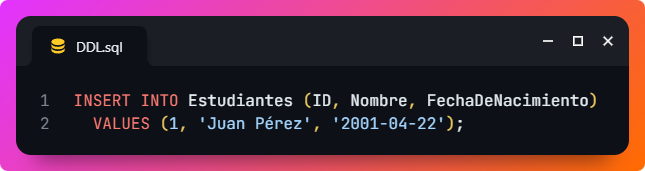
- INSERT: inserta nuevos registros en una tabla. Por ejemplo, este comando inserta un nuevo estudiante en la tabla.
- SELECT: recupera datos de una o más tablas. Por ejemplo, este comando selecciona todos los registros de la tabla Estudiantes.
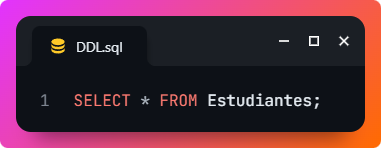
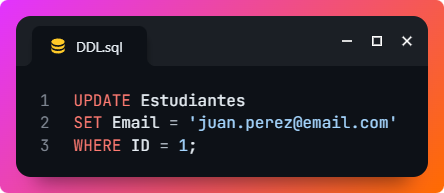
- UPDATE: modifica los datos existentes en una tabla. Por ejemplo, este comando actualiza el correo electrónico del estudiante con ID 1.
- DELETE: elimina registros de una tabla. Por ejemplo, este comando elimina el registro del estudiante con ID 1.

En las prácticas asociadas a este tema, veremos todas las posibilidades que tenemos cuando trabajamos con estos y otros comandos de SQL:
✔️ Prácticas del Lenguaje de Manipulación de Datos (DML)
Vistos ambos lenguajes (definición y manipulación de datos) merece la pena ahondar y dedicar unos minutos más a ver otro ejemplo adicional completo que nos permita centrarnos en las consultas.
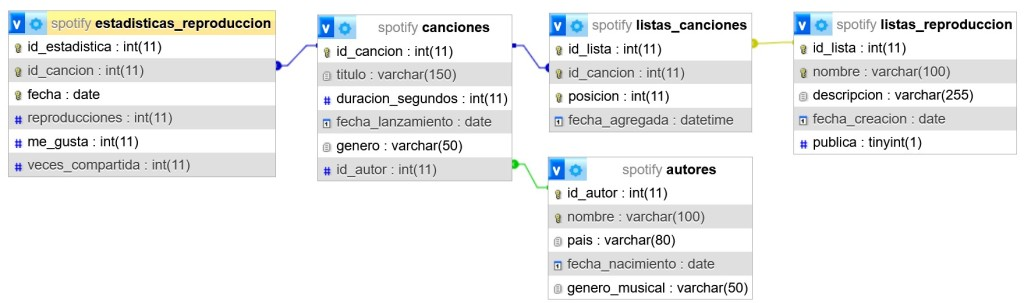
Para ello vamos a trabajar con una base de datos llamada spotify con la siguiente estructura:
Para que no perdamos tiempo en crear tablas, restricciones, relaciones e inserción de datos, puedes crear toda la base de datos ya rellena de datos reales importando este fichero directamente en su sistema gestor de bases de datos MySQL (debes descomprimirlo e importar el archivo SQL). Para practicar, intenta resolver las siguientes consultas.